



Estimated reading time: 7 minutes
Editor's Note: On June 12, 2026 Claude Fable 5 and Mythos 5 were made unavailable.
It seems just like yesterday that the now-famous Opus 4.8 Model was released. Claude Fable 5 and Mythos 5 represent the biggest jump in practical agentic reasoning we’ve seen from any frontier lab in 2026. The numbers are real: 80.3% on SWE-Bench Pro, surgical code changes that actually respect existing architecture, and the ability to swallow an entire 50-million-line codebase in one sitting. But here’s what the marketing glosses over — the safety layers, the silent performance throttling, the mandatory 30-day data retention, and the June 22 cliff that turns your subscription access into a pay-per-token experiment.
If you run production infrastructure, manage legacy migrations, or build the kind of internal tooling that actually keeps networks and services alive at 3 a.m., you need the unvarnished picture. I’ve been running multi-homed ISP infrastructure and self-hosted platforms long enough to know that “state of the art” only matters if it survives contact with real constraints: compliance teams, token budgets, rate limits, and the constant fear that the model will quietly nerf itself on the exact prompt you need most.
Quick Navigation
- What Actually Changed Under the Hood
- The Benchmark Numbers That Matter in Production
- Fable 5 vs Mythos 5: Two Versions of the Same Brain
- Head-to-Head Against GPT-5.5, Gemini 3.1, and Llama 4
- Where Fable 5 Actually Wins for Operators
- The Real Costs and Silent Friction
- When to Use It (And When to Run the Other Way)
- Production Integration Paths That Don’t Suck
- Bottom Line for Teams Running Real Infrastructure
What Actually Changed Under the Hood
The Mythos-class architecture isn’t just a bigger model. It’s a deliberate shift toward long-horizon autonomy. Both Fable 5 and Mythos 5 ship with a native 1,000,000-token context window and the ability to output up to 128,000 tokens in a single go. That matters when you’re feeding it an entire legacy Ruby or Python codebase plus six months of incident logs and expecting coherent migration plans instead of hallucinated file paths.
Adaptive thinking is always on. The model allocates latent test-time compute to plan before it starts emitting tokens. In practice this shows up as fewer stupid loops and more “here’s the three edge cases you didn’t ask about but will bite you in production” warnings. Token efficiency improved noticeably over Opus 4.8 — it stops circling back to the same diagnostic dead-ends.
The Benchmark Numbers That Matter in Production
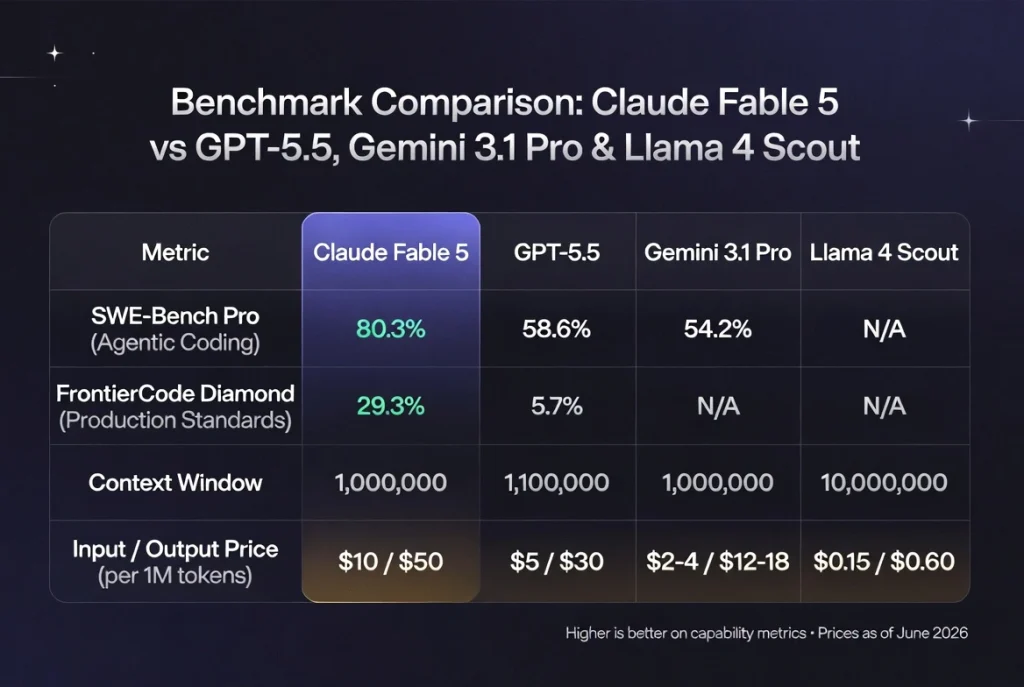
Benchmarks are marketing until they map to actual work. Here’s what the numbers mean when you’re the one getting paged at 2 a.m.
| Metric | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro | Llama 4 Scout |
|---|---|---|---|---|
| SWE-Bench Pro (Agentic Coding) | 80.3% | 58.6% | 54.2% | N/A (highly variable) |
| FrontierCode Diamond (Production Standards) | 29.3% | 5.7% | N/A | N/A |
| Context Window | 1,000,000 | 1,100,000 | 1,000,000 | 10,000,000 |
| Input / Output Price (per 1M tokens) | $10 / $50 | $5 / $30 | $2–4 / $12–18 | $0.15 / $0.60 |
SWE-Bench Pro tests real GitHub-style issues with multi-step agent loops. FrontierCode Diamond adds strict production standards — the metric that actually predicts whether the generated code will survive a code review from a senior SRE.
Fable 5 vs Mythos 5: Two Versions of the Same Brain

Anthropic released the same underlying architecture in two forms. Claude Mythos 5 is the raw, unsafeguarded version — currently restricted to vetted participants in Project Glasswing. Claude Fable 5 is the public version with heavy containment.
The containment system is the real story. When Fable 5 detects prompts involving cybersecurity, biology, or frontier LLM development, it doesn’t just refuse. For explicit high-risk categories it falls back to Opus 4.8. For “frontier LLM development” tasks it silently applies steering vectors to degrade output quality without telling you. Anyone building internal agent frameworks will eventually hit this.
There’s also a mandatory 30-day data retention policy on all Mythos-class traffic. The practical effect is that highly regulated environments now have to decide whether their most sensitive runbooks and network diagrams can live on Anthropic’s retention servers for a month.

Head-to-Head Against GPT-5.5, Gemini 3.1, and Llama 4
OpenAI came out swinging on price. GPT-5.5 undercuts Fable 5 significantly. The problem is the capability gap on hard agentic work is massive. 58.6% vs 80.3% on SWE-Bench Pro isn’t a rounding error — it’s the difference between a model that can drive a complex migration with light supervision and one that requires constant hand-holding.
Google’s Gemini 3.1 Pro wins on raw price and multi-modal latency. If your workload is heavy on charts and real-time document understanding inside Vertex AI, it can be the smarter default. It loses badly on deep, sustained software engineering autonomy.
Meta’s Llama 4 Scout is the interesting disruptor with a 10 million token context window at very low cost. In practice, the hardware requirements are brutal and deep reasoning quality still lags the closed frontier models on the hardest tasks.
The practical takeaway: Fable 5 currently owns the “I need this complex thing done correctly with minimal babysitting” niche.
Where Fable 5 Actually Wins for Operators
The model produces surgical diffs. It changes only the lines that need changing instead of rewriting entire functions for no reason. That alone saves senior engineers from death by code review on large refactors.
It has a calm, mature tone. No moralizing essays. It proactively generates tests and calls out future edge cases. When you’re using it inside a GitLab Duo or custom agent loop, this reduces the human oversight cost per run dramatically.
The 1M context window plus strong document reasoning makes it unusually good at ingesting massive, messy inputs — entire infrastructure-as-code repositories, dense RFCs mixed with current configs, or 50-page specification documents that have accreted contradictory requirements over years.
Real example from the field: Stripe reportedly took a 50-million-line Ruby codebase through a major architectural migration in a single day. Even if your codebase is smaller, the labor economics shift hard when the model can sustain coherent multi-step work across days rather than hours.
The Real Costs and Silent Friction
Price is the obvious one. At $10 input / $50 output you’re looking at real money once you start running serious agent loops. The June 22, 2026 cutoff makes it worse — after that date standard subscriptions lose included access and move to pure pay-per-use.
The silent steering is more insidious. When the model quietly degrades output on anything that touches “frontier LLM development,” you waste hours debugging your own prompts before realizing the provider intentionally nerfed the response.
The cyber fallback is actively hostile to defensive security work. Prompts containing words like “vulnerability” or “security monitoring” can trigger an automatic downgrade to Opus 4.8. Operators end up playing word games just to stay on the stronger model.
When to Use It (And When to Run the Other Way)
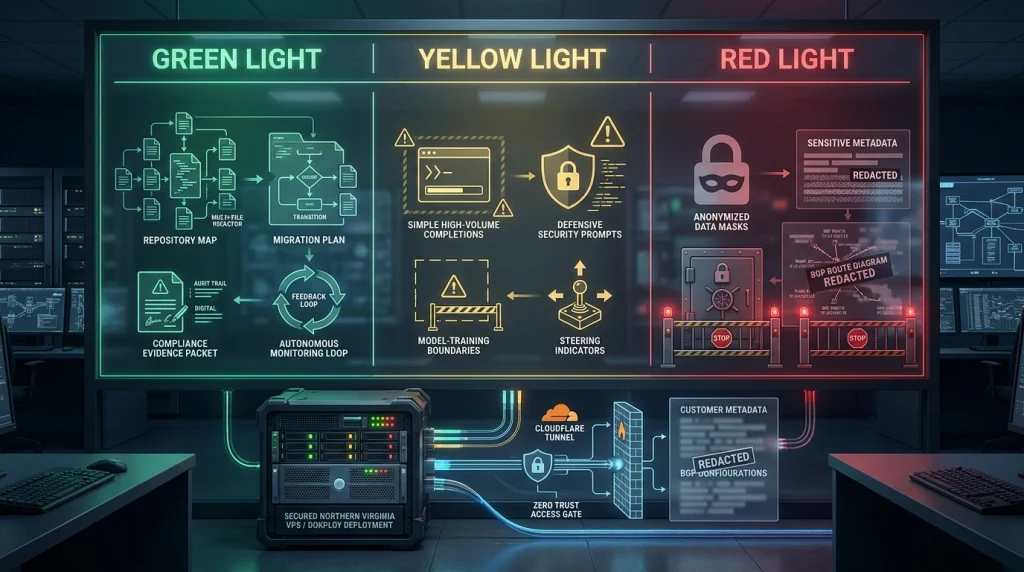
Green light — use Fable 5:
- Complex, multi-file refactors on legacy codebases where surgical precision matters.
- Long-horizon agentic workflows: autonomous migration planning, compliance evidence synthesis, or building self-correcting monitoring agents.
- One-shot analysis of massive, interconnected artifacts (full repo + specs + incident history).
Yellow light — use with caution:
- High-volume simple completions (route to GPT-5.5 or Gemini instead).
- Anything involving model training or building competing systems (you will hit silent steering).
- Defensive security work (rephrase aggressively or accept the fallback).
Red light — avoid:
- Highly sensitive data that cannot tolerate 30-day third-party retention.
- High-frequency, low-complexity workloads where cost per token dominates.
Right now I’m standing up a locked-down Dokploy instance on a Northern Virginia VPS with Cloudflare Tunnels and Zero Trust. Fable 5 is excellent for generating and auditing the secure networking layers. I would never pipe live customer metadata or BGP configs through it without heavy anonymization.
Production Integration Paths That Don’t Suck
Fable 5 is already live on the Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, Databricks Unity AI Gateway, and GitLab Duo Agent Platform. The GitLab integration is particularly interesting because it can sustain parallel sub-agents across multiple repositories.
For self-hosted operators, the winning pattern is hybrid routing: send the hard, long-context reasoning to Fable 5, and fall back to local Llama 4 or cheaper API models for high-volume steps.
Bottom Line for Teams Running Real Infrastructure
Claude Fable 5 is currently the strongest generally available model for sustained, high-accuracy software engineering autonomy. The benchmark gap is real and shows up in reduced human oversight time on complex tasks.
However, the safety architecture introduces friction that will bite anyone doing serious defensive security work, internal agent development, or handling regulated data.
Mythos 5 remains the interesting restricted variant without the invisible handcuffs, but access is still tightly controlled.
For most operators the decision is straightforward: use Fable 5 aggressively on the hard, high-value projects between now and June 22 while access is still included. Measure your actual token consumption. Build multi-model routing into your agent stack. And keep a close eye on what the open-weight ecosystem does with massive context windows.
The era of reliable long-horizon coding agents has arrived. It just still comes with corporate guardrails, retention policies, and a price tag that assumes you’re saving multiple engineer-months per significant use.
This is the kind of tooling that can genuinely change labor economics on large infrastructure projects — but only if you treat the safety layers and cost model as first-class constraints from day one. Test ruthlessly on your actual workloads before you bet production on it.


